多种高光谱数据格式的读写和可视化

上一阶段我们介绍了如何在Python中对多光谱数据进行分析,接下来将介绍如何在python中进行高光谱分析和应用的一些案例。本篇先聊聊不同格式高光谱数据的读取及可视化展示方法,同时也向大家介绍一下常用的高光谱数据集。
- envi、tiff、h5、csv、mat格式高光谱数据读写方法
- 高光谱头文件编辑,真/假彩色显示、光谱数据可视化等
- 常用高光谱数据介绍
# 将使用spectral,scipy,gdal,h5py,pandas作为数据读写的主要函数库
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import cv2
from osgeo import gdal, osr, ogr, gdalconst
import os,glob,time
from scipy.io import loadmat,savemat
import spectral
import spectral.io.envi as envi
from spectral import principal_components
import seaborn as sns
import pandas as pd
import h5py
import importlib
from utils import * #之前分享过的function都放到了utils里,此文档不在展示,文末回复关键字获取
import sys,importlib
from ordered_set import OrderedSet
importlib.reload(sys.modules['utils'])# 在需要重新加载的地方调用 reload() 函数1 matlab格式高光谱数据读写
Urban 是高光谱分解研究中使用最广泛的高光谱数据之一。 有 307x307 个像素,每个像素对应一个 2x2 平方米的区域。 在此图像中,有 210 个波长范围从 400 nm 到 2500 nm,因此光谱分辨率为 10 nm。 移除通道 1-4、76、87、101-111、136-153 和 198-210 后(大气影响),我们保留 162 个通道。 Ground Truth 有 3 个版本,分别包含 4、5 和 6 个端元,本案例中使用的是4个端元的版本。
参考文献:Linda S. Kalman and Edward M. Bassett III “Classification and material identification in an urban environment using HYDICE hyperspectral data”, Proc. SPIE 3118, Imaging Spectrometry III, (31 October 1997);
数据下载地址: - https://rslab.ut.ac.ir/data - http://lesun.weebly.com/hyperspectral-data-set.html - https://erdc-library.erdc.dren.mil/jspui/handle/11681/2925
# 读取mat文件,影像和头文件信息都可以用自定形式存储
urban = loadmat('./data/Urban_R162.mat')
print(urban.keys()) # 查看mat文件中的变量名
SlectBands,nRow, nCol, nBand, Y, maxValue=(urban['SlectBands'],urban['nRow'], urban['nCol'], urban['nBand'], urban['Y'],urban['maxValue']) #显示mat中的数据
print(SlectBands.shape,nRow, nCol, nBand, Y.shape,maxValue)dict_keys(['__header__', '__version__', '__globals__', 'SlectBands', 'nRow', 'nCol', 'nBand', 'Y', 'maxValue'])
(162, 1) [[307]] [[307]] [[210]] (162, 94249) [[1000]]def get_hsi_by_band(hsi_img, bands_to_get):
bands=np.array(bands_to_get)
hsi_out = hsi_img[:,:,[int(m) for m in bands]]
return hsi_outurban_hsi=np.transpose(Y.reshape((162, 307, 307)),(1,2,0)) # 将Y的维度转换为(nRow,nCol,nBand)
print(urban_hsi.shape)
urban_b50=get_hsi_by_band(urban_hsi, [50])
urban_rgb=get_hsi_by_band(urban_hsi, [49,31,6])
plot_2_img(urban_rgb,urban_b50,'rgb','band 50') # 详细代码见utils.py(307, 307, 162)
# 将真彩色影响保存为.mat文件
out_rgb=np.transpose(urban_rgb, (2, 0, 1))
savemat('./data/urban_rgb', {'rgb': urban_rgb})# 读取mat文件
urban_end = loadmat('./data/Urban_R162_end.mat')
print(urban_end.keys()) # 查看mat文件中的变量名
cood,A, M, nEnd, nRow, nCol=(urban_end['cood'],urban_end['A'],urban_end['M'],urban_end['nEnd'],urban_end['nRow'],urban_end['nCol']) #显示mat中的数据
print(cood.shape,A.shape, M.shape, nEnd, nRow, nCol)
label=[str(label[0]) for label in np.squeeze(cood)]def show_spectral(data, label, title='Spectral Signature'):
fig = plt.figure(figsize=(8, 4))
plt.style.use('seaborn')
plt.plot(data, label=label)
plt.xlabel('Bands', fontweight='bold', fontname='Times New Roman', fontsize=12)
plt.ylabel('Reflectance', fontweight='bold', fontname='Times New Roman', fontsize=12)
plt.title(title)
plt.legend(loc='upper left', bbox_to_anchor=(1, 1))
plt.tight_layout()
plt.show()
show_spectral(M,label,'Spectral Signature of Endmembers')
2 ENVI格式数据读写
Cuprite是高光谱解混研究最基准的数据集,覆盖美国内华达州拉斯维加斯的Cuprite,有224个通道,范围从370 nm到2480 nm。 去除噪声通道(1-2 和 221-224)和吸水通道(104-113 和 148-167)后,剩下 188 个通道,其中包含 14 种矿物。 由于相似矿物之间存在微小差异,端元被整合为目前的12个端元,具体包括:“明矾石”、“钙铁榴石”、“铵长石”、“蓝线石”、“高岭石1”、“高岭石2”、“白云母”、“蒙脱石”、“绿脱石”、“镁铝榴石”、“榍石”,“玉髓”。
利用 spectral库读取envi格式高光谱数据
# 读取envi格式高光谱数据文件
filepath='./data/Cuprite_ref188.hdr'
cup_hsi =envi.open(filepath)
spectral.imshow(cup_hsi, (27, 18, 9))
获取、编辑、写入影像头文件信息
metadata=cup_hsi.metadata
rows, cols, bands = cup_hsi.shape
wavelength_units = metadata['wavelength units'] # 获取波长单位
file_type=metadata['file type'] # 获取文件类型
wl=cup_hsi.bands.centers # 获取波长
# # 打印数据的信息
print('长',rows,'宽',cols,'波段数',bands,'波段范围',[np.min(wl), np.max(wl)],'波长单位',wavelength_units,'文件类型',file_type)
# print(metadata) #所有头文件信息都保存在metadata中长 500 宽 500 波段数 188 波段范围 [385.262512, 2477.196045] 波长单位 Nanometers 文件类型 ENVI Standard# 尝试将波长单位改为微米,并将波长信息及单位信息重新写入头文件中
metadata['wavelength units']='Micrometers'
mwl=np.array(wl)/1000.0
metadata['wavelength']=list(mwl)
envi.write_envi_header(filepath,metadata)# 确认修改后的波长信息
print(cup_hsi.metadata['wavelength'][0])0.385262512提取真彩色三波段数据,继承原数据的投影信息,转换成bil格式,创建新的头文件并输出成envi格式影像
rgb=cup_hsi[:,:,[27, 18, 9]] #提取真彩色波段数据
# 继承原有数据头文件信息中不变部分
newmetadata = {key: metadata[key] for key in ['samples', 'lines', 'file type', 'data type', 'map info', 'file type', 'file type']}
newmetadata['bands']='3'
newmetadata['interleave']='bil' #定义数据写入方式
newmetadata['wavelengths']=list(mwl[[27, 18, 9]]) #定义波长信息
print(newmetadata)
# 将rgb数据保存为.img格式,可用envi软件打开确认
envi.save_image('./data/cuprite_rgb.hdr', rgb, dtype=np.int16,force=True,interleave='bil',metadata=newmetadata)3 tiff格式数据读写
Pavia University是 ROSIS 传感器在意大利北部帕维亚上空飞行时采集到的场景。帕维亚大学的波段数量为 103 个。图像尺寸是 610×610 像素,但图像中存在一些空值需要在分析之前必须丢弃。 几何分辨率为1.3米。 地物被划分为 9 个类别。由意大利帕维亚大学电信与遥感实验室的 Paolo Gamba 教授提供。
gdal是目前遥感数据处理中非常常用的库,跨平台兼容性好,支持多种数据格式,支持数据投影、重采样、裁剪、数据统计等各种操作,还集成多种地理空间库如OGR、Proj等,功能十分强大
paviau=gdal.Open('./data/paviaU.tif', gdal.GA_ReadOnly)
img_bands = paviau.RasterCount#band num
img_height = paviau.RasterYSize#height
img_width = paviau.RasterXSize#width
img_arr = paviau.ReadAsArray() #获取数据
geomatrix = paviau.GetGeoTransform()#获取仿射矩阵信息,本案例数据无地理投影信息
projection = paviau.GetProjectionRef()#获取投影信息,本案例数据无地理投影信息
print(img_bands,img_height,img_width,img_arr.shape,geomatrix,projection)103 610 340 (103, 610, 340) (0.0, 1.0, 0.0, 0.0, 0.0, 1.0) # 通过设置读取数据的起始位置和大小,可以读取数据的子集
subset_data = paviau.ReadAsArray(0, 50, 250, 350)
paviau_gt=gdal.Open('./data/paviaU_gt.tif', gdal.GA_ReadOnly)
lab_arr=paviau_gt.ReadAsArray(0, 50, 250, 350)
img_arr=subset_data.transpose(( 1, 2,0))
plot_2_img(img_arr[:,:,[45,15,7]]/8000.0,lab_arr,'RGB','Ground True')
# 将裁剪后的影像导出为tiff格式,用法前面教程已经介绍过,具体见utils.py
Write_Tiff(subset_data,geomatrix,projection,'./data/paviaU_sub.tif')from scipy.stats import kde
def band_density(waveband_1, waveband_2,waveband_1_index,waveband_2_index):
# 计算两个波段的相关性
correlation = np.corrcoef(waveband_1.flatten(), waveband_2.flatten())[0, 1]
print("Correlation coefficient between the two bands:", correlation)
# 生成密度图数据
xy = np.vstack([waveband_1.flatten(), waveband_2.flatten()])
density = kde.gaussian_kde(xy)(xy)
# 绘制散点图
fig = plt.figure(figsize=(8, 5))
plt.style.use('seaborn')
plt.scatter(waveband_1.flatten(), waveband_2.flatten(), c=density, s=1,cmap='jet')
plt.xlabel('Band ' + str(waveband_1_index))
plt.ylabel('Band ' + str(waveband_2_index))
plt.title('Scatter Plot: Band ' + str(waveband_1_index) + ' vs Band ' + str(waveband_2_index))
# 添加色标
colorbar = plt.colorbar()
colorbar.set_label('Density')
plt.show()# 查看两个波段的相关性,间隔10个波段依然具有较高的相似度,可见高光谱数据冗余度很高
from scipy.ndimage import zoom
# 使用zoom函数进行1/2重采样
banda = zoom(img_arr[:,:,45], 0.5, order=1)
bandb = zoom(img_arr[:,:,55], 0.5, order=1)
band_density(banda,bandb,45,55)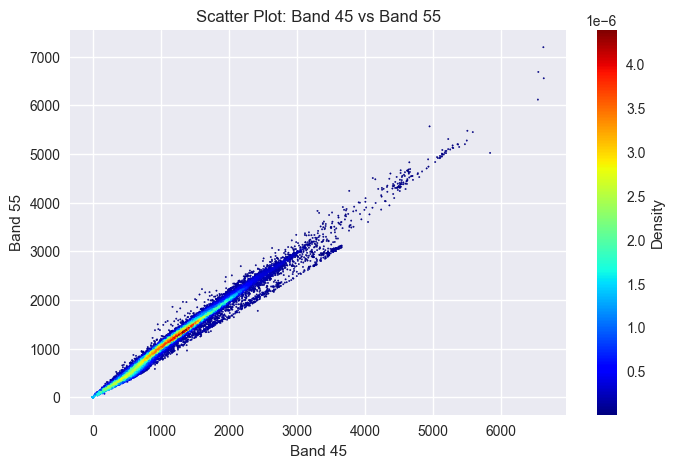
4 csv格式数据读取
Indian pines数据由 AVIRIS 传感器在印第安纳州西北部的 Indian Pines 测试场地采集,由 145×145 像素和 224 个光谱反射带组成,波长范围为 0.4–2.5 × 10-6 米。 该场景是一个较大场景的子集。 印度松树场景包含三分之二的农业和三分之一的森林或其他天然多年生植被。 有两条主要的双车道高速公路、一条铁路线,以及一些低密度住房、其他建筑结构和较小的道路。 由于该场景是在 6 月份拍摄的,因此一些农作物(玉米、大豆)正处于生长早期阶段,覆盖率不到 5%。 可用的基本事实被指定为十六个类别,并且并非全部都是相互排斥的。 我们还通过去除覆盖吸水区域的谱带,将谱带数量减少到 200 个:104-108、150-163、220。印度松树数据可通过 Pursue 大学的 MultiSpec 网站获得。
df = pd.read_csv('./data/Indian_pines.csv')
df.head()
indianp= df.iloc[:, :-1].values
indianp_label = df.iloc[:, -1].values
print(indianp.shape,indianp_label.shape,np.max(indianp))(21025, 200) (21025,) 9604indianp_img=np.reshape(indianp,(145,145,200))
indianp_lab=np.reshape(indianp_label,(145,145))
plot_2_img(indianp_img[:,:,[29,19,9]]/10000.0,indianp_lab,'RGB','Ground True')
# 输入波段号,查看不同波段的箱线图
plt.figure(figsize=(10,4))
n = int(input('Enter the band Number(1-200) :'))
sns.boxplot( x=indianp_label, y=indianp[:,n], width=0.3)
plt.title('Box Plot', fontsize= 16)
plt.xlabel('Class', fontsize= 14)
plt.ylabel(f'Band-{n}', fontsize= 14)
plt.show()
5 h5格式数据读取
Jasper Ridge 是一个流行的高光谱数据集。 其中有 512x614 像素。 每个像素均记录在 380 nm 至 2500 nm 的 224 个通道中。 光谱分辨率高达9.46nm。 本次提供的是裁剪版本大小事 100x100。 删除通道 1-3、108-112、154-166 和 220-224后,我们保留 198 个通道。 该数据中有四个潜在的端元:“#1 Road”、“#2 Soil”、“#3 Water”和“#4 Tree”。
hdf5_path = './data/jasper_ridge.hdf5'
fd = h5py.File(hdf5_path, 'r')
print(fd.keys())<KeysViewHDF5 ['abundance', 'end_name', 'endmember', 'image']># hdf5格式可以存储多个数据类型,支持切片读取
data=np.array(fd['image']) #data=fd['image']或fd['image'][:,:,:20]此时读取数据并不占用内存,只有对数据操作后才会占用内存
abn=np.array(fd['abundance'])
end=np.array(fd['endmember'])
label_bytes = fd['end_name'][:]
label = np.array([s.decode('utf-8') for s in label_bytes])
print(label,end.shape,abn.shape,data.shape)['1-tree' '2-water' '3-dirt' '4-road'] (198, 4) (4, 100, 100) (198, 100, 100)pc = principal_components(data.transpose((1,2,0)))
pcdata = pc.reduce(num=10).transform(data.transpose((1,2,0)))
plot_2_img(pcdata[:,:,:3],np.argmax(abn,axis=0),' First 3 PCA','Abundance Map',cmap2='Blues_r')
hdf5_path = './data/jasper_ridge_pca3.hdf5'
with h5py.File(hdf5_path, 'w') as f:
f['image'] = pcdata[:,:,:3]
f['class'] = np.argmax(abn,axis=0)
f.close()
print("HDF5文件已创建成功!")6 常用高光谱数据集
url1:https://rslab.ut.ac.ir/data
url2:https://www.iotword.com/7117.html
请关注微信公众号【45度科研人】获取更多精彩内容,欢迎后台留言!
